Cluster
SubHosting's high availability cluster solutions provide horizontal scaling by connecting multiple servers which work in tandem to share workload and help serving thousands of simultaneous visitors with a very high uptime close to 100%. High availability and reliability are achieved by deploying redundant servers for different server roles.
Do you really need a high availability cluster?
You have an exceptional growth in the business or want to release more products/services which attracts several thousands of vistors to your website and the visitor traffic increases day by day. This may push the dedicated hosting server to its limits and slow down the web site eventually. Upgrading hardware (vertical scaling) on the dedicated server can help immediately for a short term, but it cannot be a long term productive solution. Then, you need a server cluster.
Configuration setup is based on your needs, please contact us to discuss about your service and requirements. Following are some of typical high availability cluster configurations offered by us.
CLUSTER1
This is our entry level cluster which helps you leverage the power of a cluster at an affordable price. Each server role (web, database etc) is assigned a seperate server and thus workload is distributed. Following network diagram shows a typical cluster1 configuration which has a firewall and load balancer, a web server, a database server and an optional cPanel server for email and DNS.
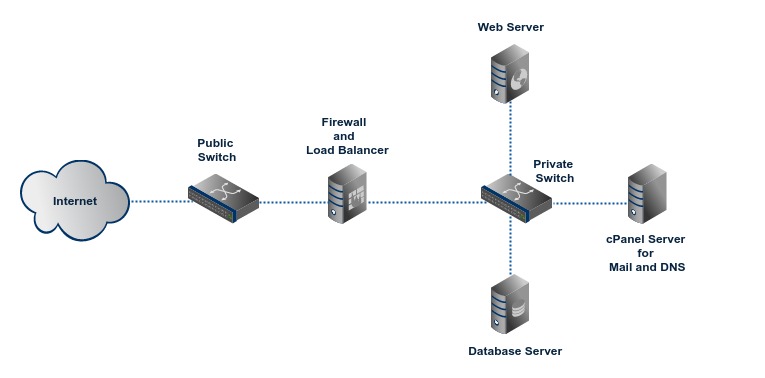
All the servers are connected to a private network and servers communicate among them over this network. The load balancer receives visitor connections from Internet and distributes visitors among the servers. Backup of data is stored on our shared backup storage system.
Depending on the server software stack for your web application, web server can run Apache, nginx, Node.js etc and database server can run a RDBMS (Relational Database Management System) such as MySQL, PostgreSQL etc or a NoSQL database system such as MongoDB, CouchDB, Aerospike etc.
CLUSTER2
Cluster2 adds redundancy to critical server roles by using at least two mirror servers for each role. Redundancy provides higher uptime and helps serving more concurrent visitors. If a server has a problem, service will be still available from its mirror server. A typical configuration has a firewall and load balancer, two web servers, two database servers and an optional cPanel server for email and DNS. Backup is stored on our shared backup storage system.
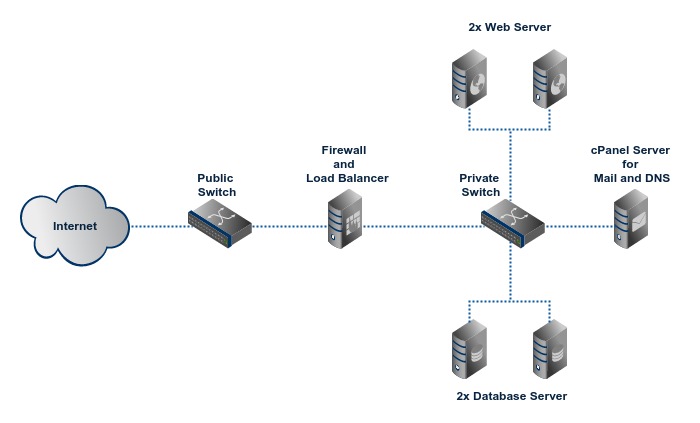
Since the web servers are mirrors of each other, there should be a way to share data among web servers and ensure integreity of data. It can be achieved using a reliable network file sharing method such as NFS, GlusterFS or a simple file synchronization using rsync. The actual file sharing method depends on nature of application and cluster design.
Data sharing among database servers is achieved using replication and/or sharding. All major RDBMS and NoSQL servers support replication and sharding.
CLUSTER3
Cluster3 avoids all single points of failure by using redundancy for every essential server roles. A group of two or more servers is used for each role. It provides the highest level of uptime and throughput for a cluster hosted in a single datacenter. A typical configuration has two firewall and load balancer servers, four web servers, three database servers, two optional cPanel servers for email and DNS and a dedicated backup server.
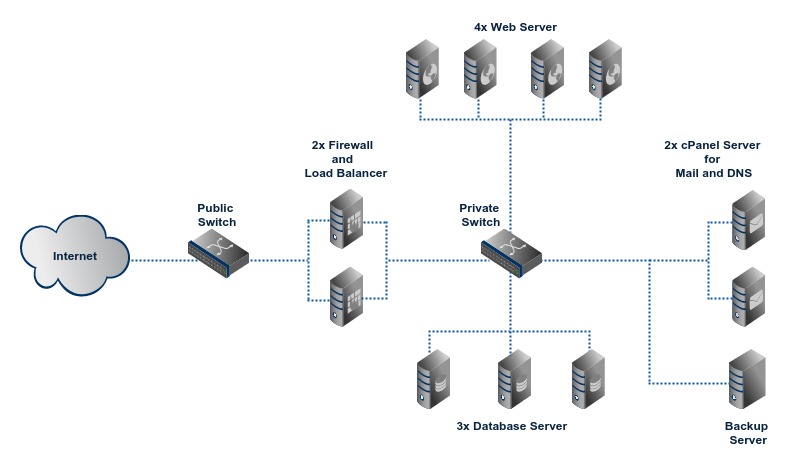
If a server in a role group is unavailable, it is automatically removed from service and other servers in the group continue to provide service. When the affected server becomes alive, integrity of data is ensured before it is put back in service.
CLUSTER4
This cluster is suited to mission critical applications which need 100% uptime. A primary cluster is replicated to one or more secondary clusters located in our other datacenter locations. Data on primary cluster is continuously replicated to secondary clusters. Fail-over is implemented using anycast routing. If datacenter of primary cluster goes out of service for any reason, one of the secondary clusters gets activated and takes over the role of primary cluster. A typical cluster4 configuration has two cluster3 setups located in two different datacenters.
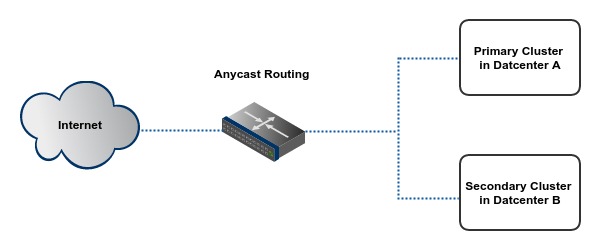
With anycast routing, the IP address used for accessing application service from cluster is advertised for multiple cluster nodes in different datacenters. Visitor connections are sent through the anycast routing infrastructure. When anycast router receives a network packet, it is forwarded to the geographically nearest cluster which may be designated as the primary cluster. Anycast router monitors health of each datacenter using an appropriate method. When a cluster becomes unhealthy it is temporarily removed from routing table until that cluster becomes healthy again.
More information
All our cluster solutions are highly scalable. Servers for various roles can be added or removed depending on visitor traffic to the cluster. For example, your web site may have a seasonal increase in visitors for a couple of weeks. To support this extra traffic, a few new servers may be added to the cluster. When the season is over, extra server can be removed from cluster.
A cluster may have high, medium and low profile server roles. It is not necessary to host all these roles into separate physical servers. Low/medium profile roles can be combined into a single server, thus reducing cost and avoiding idle resources. For example, following is the network diagram of a highly available MongoDB cluster which makes use of replication and sharding to achieve high availability:
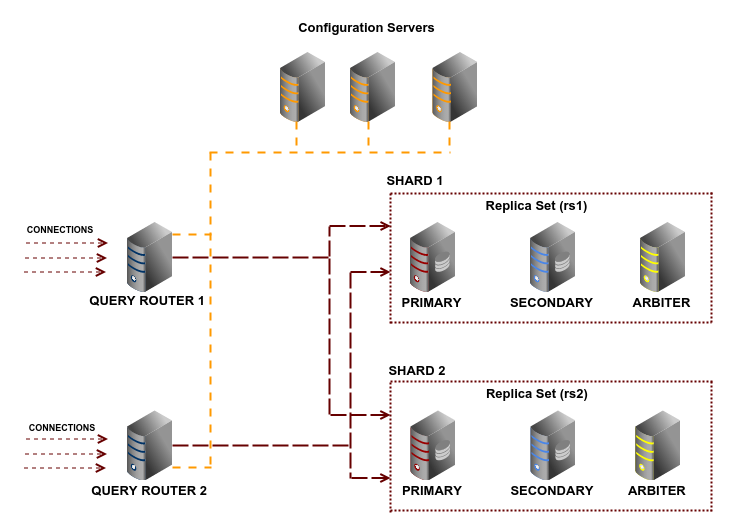
The primary and secondary MongoDB servers in the replica sets are the real workhorses. The query routers, configuration servers and arbiters are medium and low profile servers. So these servers can be hosted in VPSs (Virtual Private Servers). Even though there are 11 servers in tis cluster, it can be built using five physical servers; four for the primary and secondary MongoDB servers and one for hosting the VPSs for query router, configuration servers and arbiters.